
How to Query Large SQL Tables Efficiently Using Only the Primary Key
Do you need to query a massive SQL table with millions of rows, but there is no index on the column you care about? In this post, we’ll look at a simple technique to speed up your queries by using only the index that you do have — the primary key — to improve performance.
Including the primary key in the SQL query when no other index exists on the target table can significantly reduce the amount of database resources it takes to find the data you are looking for. This can prevent performance degradation for other users by keeping the queries running quickly and efficiently. It can also help you find the data you are looking for much more quickly. You may just need to do a little bit of work to figure out how to find the correct key values that equate to the data you are searching for.
At some point, you may need to query a large table, looking for data for which no index other than the primary key exists.
For example, maybe you want to query a log table that includes a date/time column indicating when the log was written. You want to query this table for a specific date or date range. However, for one reason or another, an index was never added to the datetime column on the log table. Fast forward a few years, and your business has taken off and millions of rows have been logged to the table. Or, maybe you have a table that stores data subject to regulations regarding how long the data must be retained, and the data in the table that is irrelevant to the data you are searching for hasn’t been moved to an archive yet.
In any case, the fact of the matter is, you may find yourself needing to query a table by a column that isn’t indexed, and the only option you will have for efficient searches is the primary key. Running a query using a non-indexed column on a very large table can be extremely resource intensive. Just one user running an inefficient query on a production database server can be enough to slow down the database processing for every user that is currently using the database.
It is, of course, best not to have to run analysis queries directly in production. Let’s face the facts, though, it’s often necessary to do so for one reason or another.
Consider a hypothetical log table named “Logs” in a Microsoft SQL Server database named “EvaluationCompany”. You may often find a table like this in a database with applications that are using a logging framework, such as Serilog or Log4J/Log4Net. For whatever reason, the development team that wrote the application decided to keep the log data in the database. The team never added an index on the LogDate column, and now, it’s impractical to add an index on the column. Maybe the company doesn’t want to incur the cost that the additional disk space needed for the index would require. Maybe the next available maintenance window to add the index is 3 months away. In any case, for the sake of our example, we’ll say it’s just not feasible to add the index to the table.
The table structure is shown below. This table has been simplified to include 3 columns: Id, LogDate and LogMessage. Here is the table structure:
For this example, I’ve loaded this test table with about 1.4 GB of test data:
Now, consider a hypothetical scenario where we need to find the first 100 log entries that occurred on January 1st, 2024. We’ll write a query for this, looking for anything where the LogDate is > ‘2024-01-01’ and ask SSMS to show us the actual execution plan. The query takes about 3 seconds to run and produces the following execution plan:
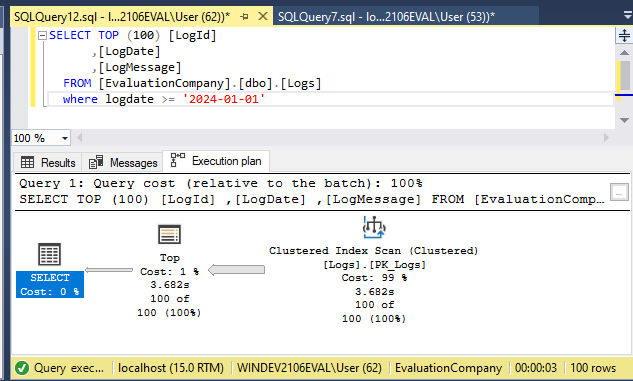
We can see from the reported execution plan that the database ran a Clustered Index Scan on the table’s primary key. This is because the primary key column is the only indexed column in the table, and that means it’s the only way the database engine has to try to run an efficient search.
3 seconds isn’t too bad, but in a real production scenario for an enterprise application, running queries on large production tables containing hundreds of gigabytes (or terabytes) of data can take several minutes to run. Queries that take that long to run are likely to affect other users of the database.
In order to mitigate this, and make our hypothetical analysis query run much more quickly, we can add the primary key to the query. To do this, we need to find the first ID that matches our criteria. There are a couple of ways to do this, but to minimize the impact on the production server as much as possible, we’ll first find the highest ID in the DB by running a query requesting the first row found when ordering in descending order by the primary key.
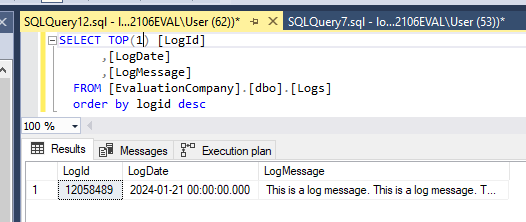
This query gives us sub second response time because the database can use the primary key when searching the data.
Now we know that our highest ID is 12,058,489. We can use this as a starting point to reduce the amount of data we need to ask the database to search. Remember, we’re looking for the first 100 rows that have a date >= ‘2024-01-01’. So, let’s take the ID we know and subtract 1,000,000 from the value. Now, let’s take that value and add it to a where clause in our query. Additionally, we now need to sort by LogId in ascending order so the older dates are found first.
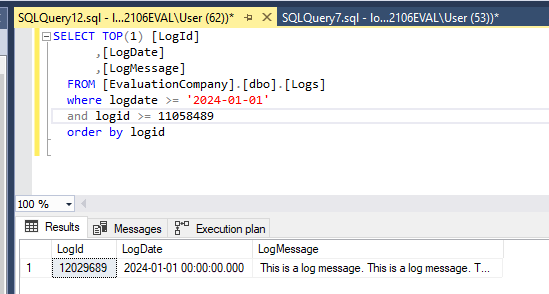
This query returned in less than a second. From there, we can increase the number of rows to 100 and run the query again and get the results we need:
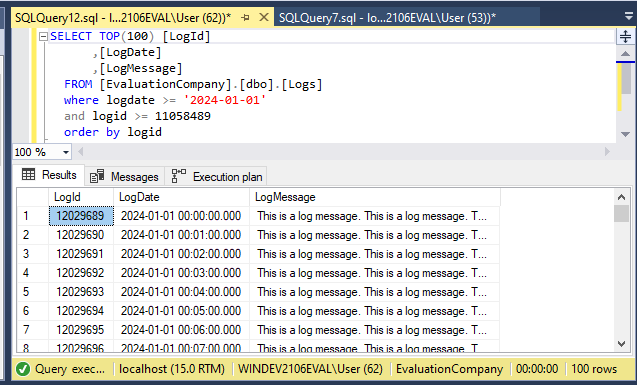
The results are returned in less than one second.
Why is this faster? By telling the database engine that we only want rows with an ID >= 11,058,489, we’ve given the database a starting point that it can use as a lookup on the primary key to reduce the subset of data it needs to search. To prove this, let’s look at the execution plan for our new query:
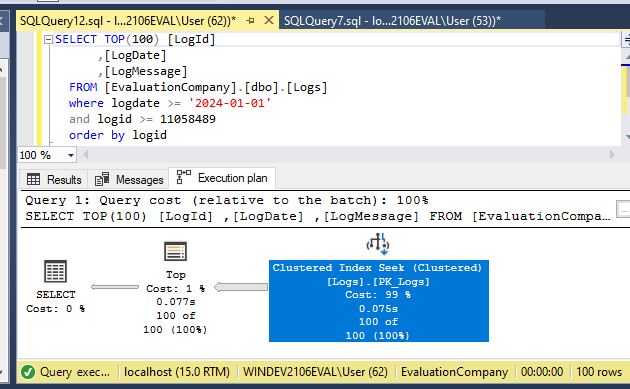
As shown in the highlighted step of the execution plan, the database is now running a Clustered Index Seek, which is a much faster operation than a Clustered Index Scan.
There are a couple of caveats that need to be mentioned here:
This technique is only intended to be used for ad-hoc analysis and querying of tables where it is important not to consume too many resources on the server and negatively impact other users. In general, I wouldn’t recommend this type of solution for application logic. Unless, of course, you really know what you are doing. You really need to know that this will work 100% of the time when used in an application. Otherwise, this could produce incorrect results or omit data that is really needed.
This solution only works if the primary key order and the order of the data you are searching for (the date in our case) are in the same order in the table. This is often the case for log tables, where data is always written sequentially in temporal order to the table. This may not be the case, however, for data where the date, or whatever value you are searching for, could potentially be changed after it has been written to the table, resulting in data that is not in the same order as the primary key.
Even with the above caveats, though, this solution can be very effective in querying production database tables without negatively impacting other users of the database.